
VideoLLaMB: Long-Context Video Understanding with Recurrent Memory Bridges




Abstract
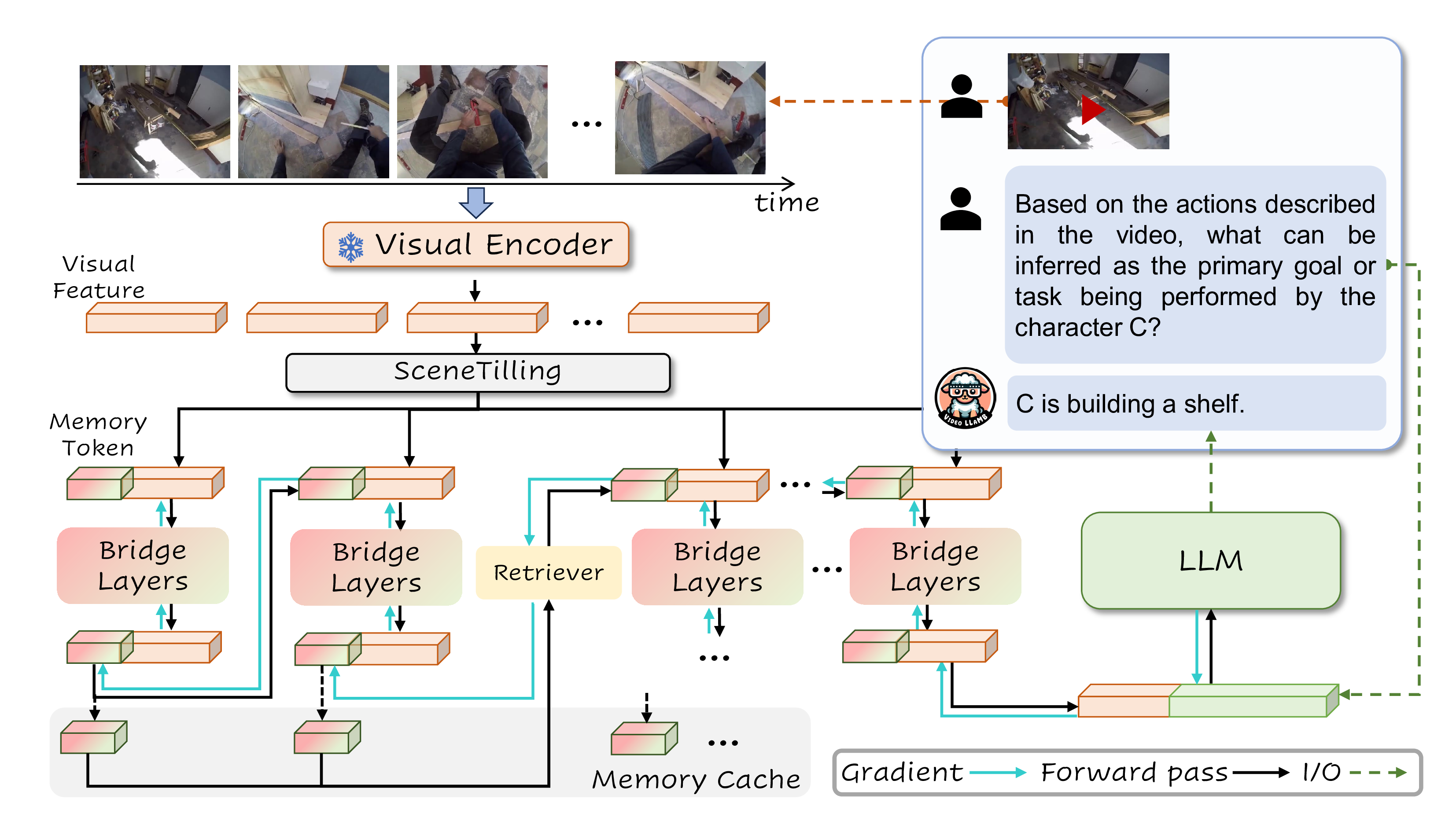
VideoLLaMB is a novel long video comprehension framework utilizing Memory Bridge Layers with recurrent memory tokens to encode 100% video content without discarding critical visual cues.
✨ Highlights:
-
Comprehensive long video understanding. VideoLLaMB-7B reached the state-of-the-art performance among 7B models trained on vicuna-7b and videochat2 video on EgoSchema, NexTQA and MVBench, reaching 8x longer video length with robust performance in comparison to PLLaVA.
-
Memory-based egocentric planning. VideoLLaMB achieves the best performance among all video-language models on EgoPlan, with an improvement of \(2.06\) over PLLaVA.
-
Training-free streaming captioning. With our SceneTiling algorithm, VideoLLaMB can capture the dynamics with in a streaming video and directly predict the streaming captions in real-time, without the need to process the entire video sequence beforehand.
-
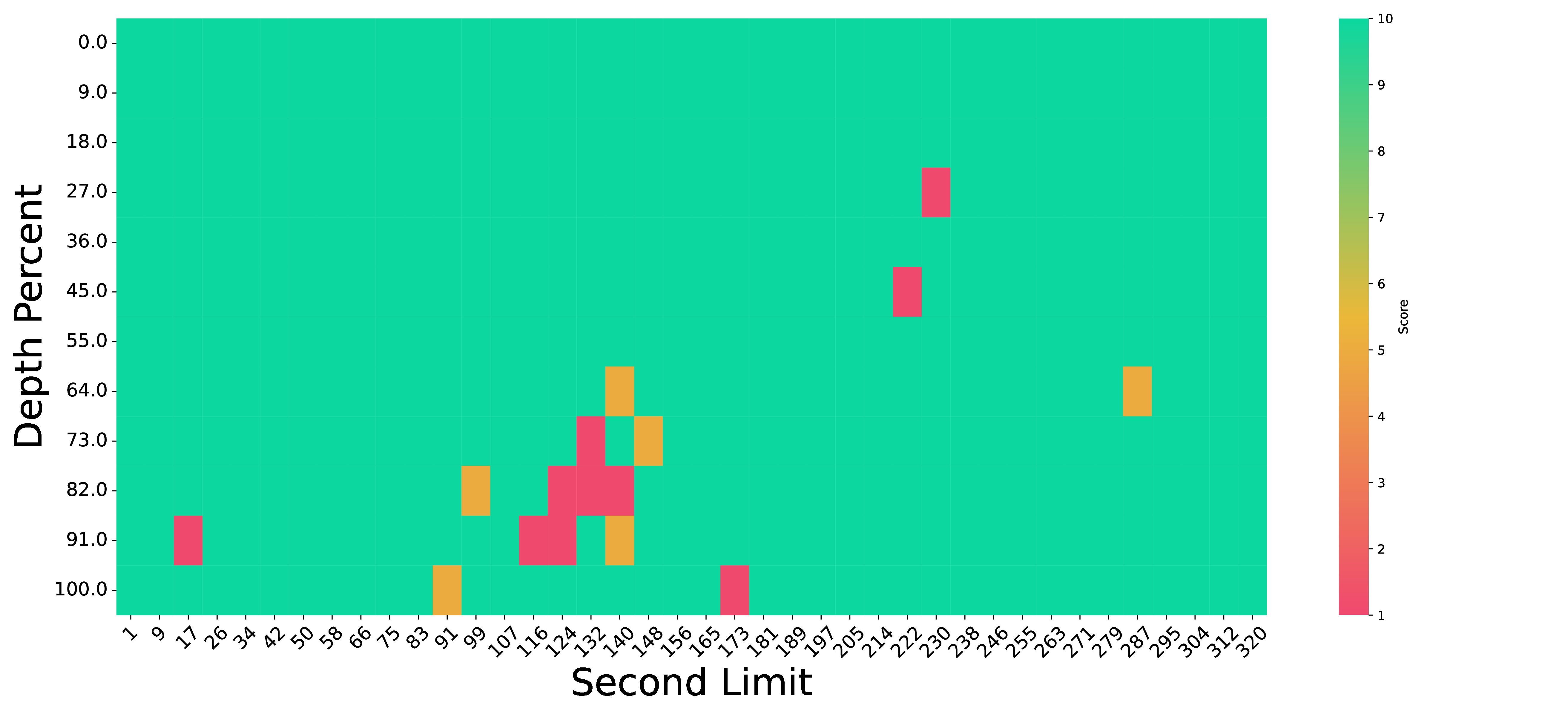
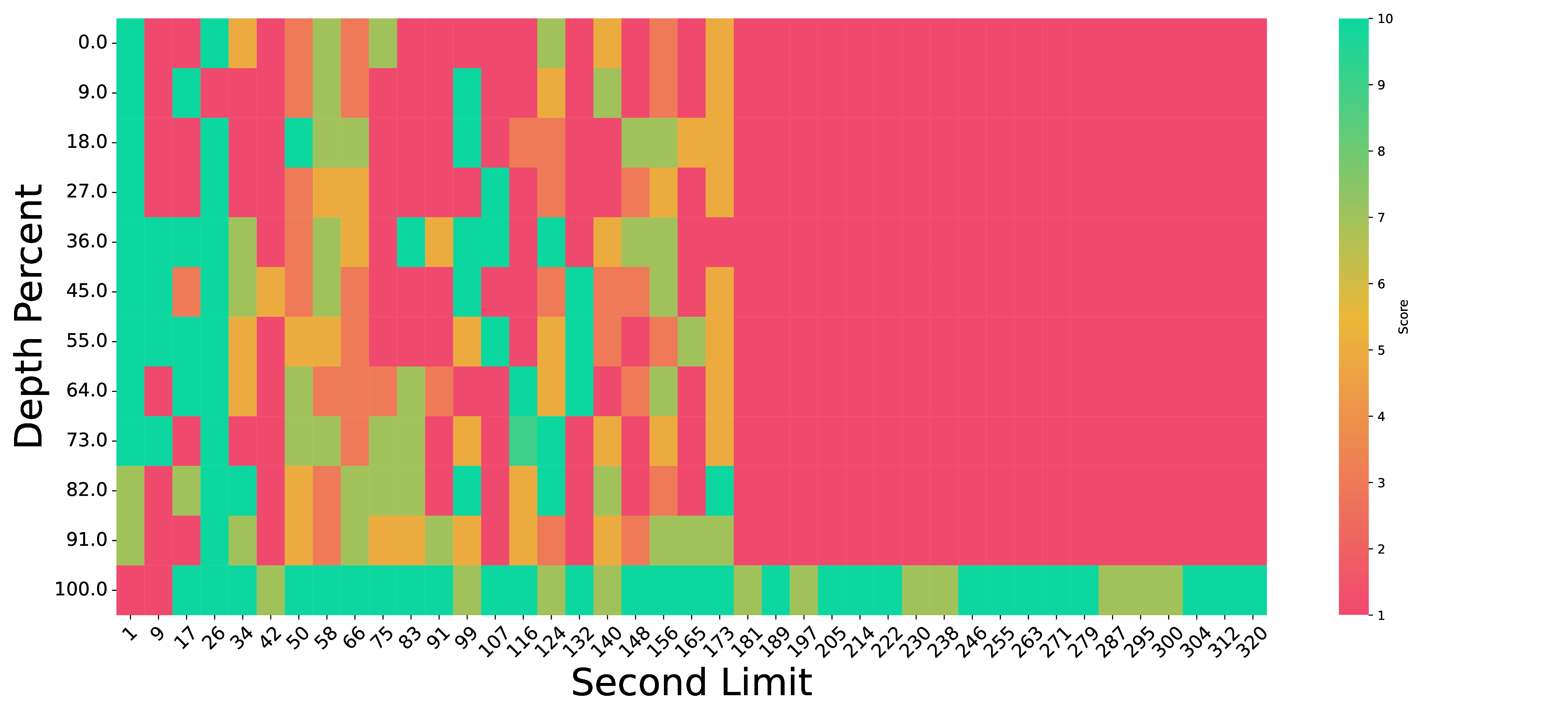
Enhanced frame retrieval on needle in a video haystack (NIAVH). We present the “Needle in a Video Haystack” (NIAVH) benchmark to evaluate long video understanding over needle of different modalities comprehensively (details 👉). In the pressure test ranging from 1 to 300 seconds in length, VideoLLaMB consistently retrieves the correct image needles at various depths, outperforming other methods as video length increases.
Long-form Video Understanding
| Method | Vision Encoder | LLM Size | AS | AP | AA | FA | UA | OE | OI | OS | MD | AL | ST | AC | MC | MA | SC | FP | CO | EN | ER | CI | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4V | GPT-4V | / | 55.5 | 63.5 | 72.0 | 46.5 | 73.5 | 18.5 | 59.0 | 29.5 | 12.0 | 40.5 | 83.5 | 39.0 | 12.0 | 22.5 | 45.0 | 47.5 | 52.0 | 31.0 | 59.0 | 11.0 | 43.5 |
| Image MLLMs | |||||||||||||||||||||||
| mPLUG-Owl-I | ViT-L | 7B | 25.0 | 20.0 | 44.5 | 27.0 | 23.5 | 36.0 | 24.0 | 34.0 | 23.0 | 24.0 | 34.5 | 34.5 | 22.0 | 31.5 | 40.0 | 24.0 | 37.0 | 25.5 | 21.0 | 37.0 | 29.4 |
| LLaMA-Adapter | ViT-B | 7B | 23.0 | 28.0 | 51.0 | 30.0 | 33.0 | 53.5 | 32.5 | 33.5 | 25.5 | 21.5 | 30.5 | 29.0 | 22.5 | 41.5 | 39.5 | 25.0 | 31.5 | 22.5 | 28.0 | 32.0 | 31.7 |
| BLIP2 | ViT-G | 2.7B | 24.5 | 29.0 | 33.5 | 17.0 | 42.0 | 51.5 | 26.0 | 31.0 | 25.5 | 26.0 | 32.5 | 25.5 | 30.0 | 40.0 | 42.0 | 27.0 | 30.0 | 26.0 | 37.0 | 31.0 | 31.4 |
| Otter-I | ViT-L | 7B | 34.5 | 32.0 | 39.5 | 30.5 | 38.5 | 48.5 | 44.0 | 29.5 | 19.0 | 25.5 | 55.0 | 20.0 | 32.5 | 28.5 | 39.0 | 28.0 | 27.0 | 32.0 | 29.0 | 36.5 | 33.5 |
| MiniGPT-4 | ViT-G | 7B | 16.0 | 18.0 | 26.0 | 21.5 | 16.0 | 29.5 | 25.5 | 13.0 | 11.5 | 12.0 | 9.5 | 32.5 | 15.5 | 8.0 | 34.0 | 26.0 | 29.5 | 19.0 | 9.9 | 3.0 | 18.8 |
| InstructBLIP | ViT-G | 7B | 20.0 | 16.5 | 46.0 | 24.5 | 46.0 | 51.0 | 26.0 | 37.5 | 22.0 | 23.0 | 46.5 | 42.5 | 26.5 | 40.5 | 32.0 | 25.5 | 30.0 | 25.5 | 30.5 | 38.0 | 32.5 |
| LLaVA | ViT-L | 7B | 28.0 | 39.5 | 63.0 | 30.5 | 39.0 | 53.0 | 41.0 | 41.5 | 23.0 | 20.5 | 45.0 | 34.0 | 20.5 | 38.5 | 47.0 | 25.0 | 36.0 | 27.0 | 26.5 | 42.0 | 36.0 |
| Video MLLMs | |||||||||||||||||||||||
| Video-LLaMA | CLIP-G | 7B | 27.5 | 25.5 | 51.0 | 29.0 | 39.0 | 48.0 | 40.5 | 38.0 | 22.5 | 22.5 | 43.0 | 34.0 | 22.5 | 32.5 | 45.5 | 32.5 | 40.0 | 30.0 | 21.0 | 37.0 | 34.1 |
| LLaMA-Adapter | ViT-B | 7B | 23.0 | 28.0 | 51.0 | 30.0 | 33.0 | 53.5 | 32.5 | 33.5 | 25.5 | 21.5 | 30.5 | 29.0 | 22.5 | 41.5 | 39.5 | 25.0 | 31.5 | 22.5 | 28.0 | 32.0 | 31.7 |
| Video-ChatGPT | ViT-L | 7B | 23.5 | 26.0 | 62.0 | 22.5 | 26.5 | 54.0 | 28.0 | 40.0 | 23.0 | 20.0 | 31.0 | 30.5 | 25.5 | 39.5 | 48.5 | 29.0 | 33.0 | 29.5 | 26.0 | 35.5 | 32.7 |
| VideoChat | CLIP-G | 7B | 33.5 | 26.5 | 56.0 | 33.5 | 40.5 | 53.0 | 40.5 | 30.0 | 25.5 | 27.0 | 48.5 | 35.0 | 20.5 | 42.5 | 46.0 | 26.5 | 41.0 | 23.5 | 23.5 | 36.0 | 35.5 |
| VideoChat2\(^\beta\) | UMT-L | 7B | 66.0 | 47.5 | 83.5 | 49.5 | 60.0 | 58.0 | 71.5 | 42.5 | 23.0 | 23.0 | 88.5 | 39.0 | 42.0 | 58.5 | 44.0 | 49.0 | 36.5 | 35.0 | 40.5 | 65.5 | 51.1 |
| PLLaVA 7B\(^\alpha\) | ViT-L | 7B | 58.0 | 49.0 | 55.5 | 41.0 | 61.0 | 56.0 | 61.0 | 36.0 | 23.5 | 26.0 | 82.0 | 39.5 | 42.0 | 52.0 | 45.0 | 42.0 | 53.5 | 30.5 | 48.0 | 31.0 | 46.6 |
| PLLaVA 13B\(^\alpha\) | ViT-L | 13B | 66.0 | 53.0 | 65.5 | 45.0 | 65.0 | 58.0 | 64.5 | 35.5 | 23.5 | 30.0 | 85.0 | 39.5 | 45.5 | 57.0 | 47.5 | 49.5 | 49.0 | 33.0 | 53.0 | 37.0 | 50.1 |
| VideoLLaMB\(^\alpha\) | ViT-L | 7B | 52.0 | 50.5 | 85.5 | 42.5 | 51.0 | 69.5 | 56.0 | 38.5 | 41.0 | 24.0 | 69.5 | 40.0 | 48.0 | 71.5 | 43.5 | 34.5 | 41.5 | 29.5 | 38.0 | 60.0 | 49.3 |
| VideoLLaMB\(^\beta\) | ViT-L | 7B | 54.5 | 47.0 | 86.5 | 44.5 | 52.0 | 79.0 | 58.5 | 32.0 | 47.0 | 33.0 | 82.5 | 40.5 | 52.0 | 82.0 | 40.5 | 37.5 | 43.0 | 31.0 | 42.5 | 60.0 | 52.5 |
Table 1. Results on MVBench multi-choice question answering. The top 3 results among 7B models are highlighted. \(\alpha\): training with data from PLLaVA. \(\beta\): training with data from MVBench.
| Model | LLM | Frames | Accuracy |
|---|---|---|---|
| GPT4-o | OpenAI API | 16 | 72.2 |
| Retrieval-based Video-Language Models | |||
| LongViViT* | - | 256 | 56.8 |
| MC-ViT-L* | - | 128 | 62.5 |
| Generative Video-Language Models | |||
| SeViLA | Flan-T5-XL | 32 | 25.8 |
| mPLUG-Owl | LLaMA-7B | 5 | 33.8 |
| VideoLLaVA | Vicuna-7B | 8 | 40.2 |
| LLaVA-NeXT-Video-DPO | Vicuna-7B | 32 | 41.6 |
| PLLaVA | Vicuna-7B | 16 (16) | 45.6 |
| PLLaVA | Vicuna-7B | 32 (16) | 43.8 |
| VideoLLaMB | Vicuna-7B | 32 (8) | 53.8 |
Table 2. Results on subset of EgoSchema under zero-shot setting. \(^*\) indicates that the model has been fine-tuned using the training data from EgoSchema.
| Model | Temporal | Causal | Description | All |
|---|---|---|---|---|
| GPT4-o | 70.3 | 78.0 | 80.8 | 76.0 |
| Retrieval-based Video-Language Models | ||||
| AIO* | 48.0 | 48.6 | 63.2 | 50.6 |
| VQA-T* | 49.6 | 51.5 | 63.2 | 52.3 |
| ATP* | 50.2 | 53.1 | 66.8 | 54.3 |
| VGT* | 52.3 | 55.1 | 64.1 | 55.0 |
| MIST-CLIP* | 56.6 | 54.6 | 66.9 | 57.1 |
| Generative Video-Language Models | ||||
| SeViLA | 61.5 | 61.3 | 75.6 | 63.6 |
| LLaMA-VID | 53.8 | 60.0 | 73.0 | 59.5 |
| VideoLLaVA | 56.9 | 61.0 | 75.0 | 61.3 |
| LLaVA-NeXT-Video-DPO | 55.6 | 61.0 | 73.9 | 61.3 |
| PLLaVA* | 62.2 | 68.5 | 79.7 | 68.2 |
| VideoLLaMB* | 66.8 | 71.6 | 78.4 | 71.1 |
Table 3. Comparison accuracy on NExT-QA. \(^*\) indicates that the instruction data includes the training data from NExT-QA.
Streaming Caption
Task: Describe the streaming video in real-time.
Egocentric Embodied Planning
| Model | LLM | Accuracy |
|---|---|---|
| GPT-4V | OpenAI API | 37.98 |
| Image-Language Model | ||
| Qwen-VL-Chat | Qwen-7B | 26.32 |
| LLaVA-1.5 | Vicuna-7B | 26.80 |
| SEED-LLaMA | LLaMA2-Chat-13B | 29.93 |
| InternLM-Xcomposer | InternLM-7B | 34.4 |
| Video-Language Model | ||
| VideoChatGPT | LLaMA-7B | 26.35 |
| Valley | LLaMA-13B | 26.17 |
| VideoLLaMA | LLaMA2-Chat-7B | 29.85 |
| LLaVA-NeXT-Video | Vicuna-7B | 28.96 |
| PLLaVA | Vicuna-7B | 30.26 |
| VideoLLaMB-7B | Vicuna-7B | 32.32 |
Table 4. Results on EgoPlan under Zero-shot setting.

Stress Test: “Needle In A Video Haystack”
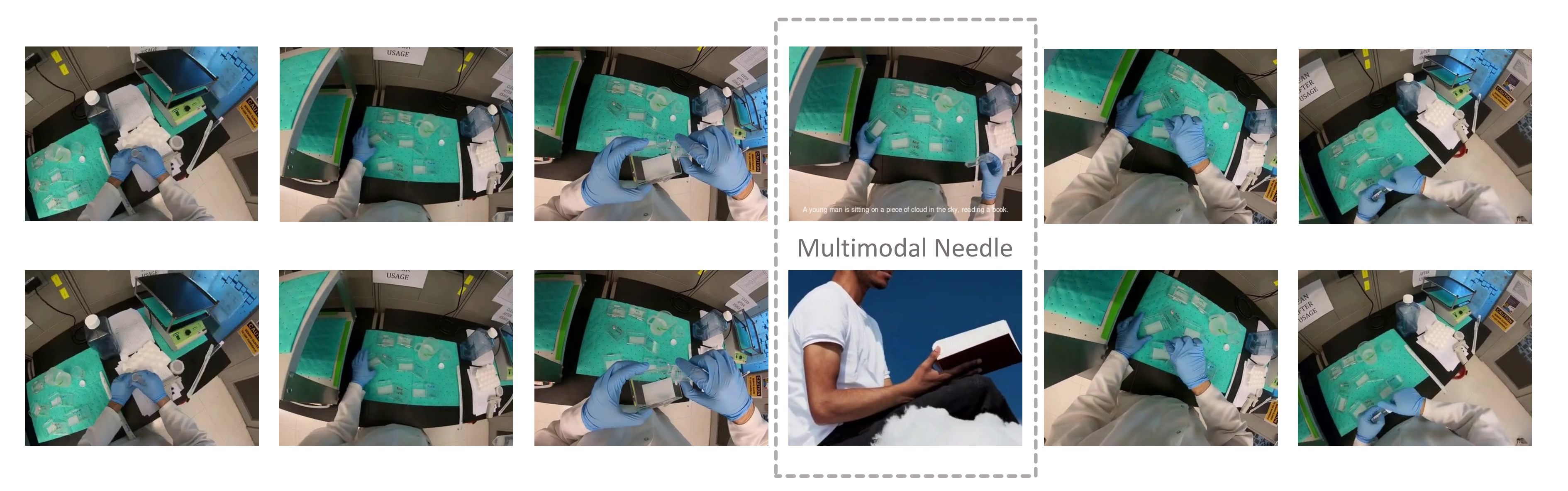
We utilize ego-centric videos from the Ego4D dataset as the “haystack”. Within this haystack, we seek to locate the “needle”, which we provide in three distinct modalities. For the textual modality, we supply a crafted description. For the image modality, we employ DALL-E to create an image that visually represents this description. For the video modality, we use Sora to generate a short video clip based on the same description. In each case, the “needle” - whether text, image, or video - is set to a duration of 1 second.
Technical Details
Scene Tiling: Segmentation with Semantics
We introduce SceneTilling, a model-free scene segmentation algorithm, to divide the entire video sequence into video segments such that each segment is semantically non-overlap with others, i.e., inter-segment coherence. Formally, given a sequence of \(n\) frames \(\{v_1, v_2, \ldots, v_n\}\), the SceneTiling algorithm is as follows.
- Compute the cosine similarity \(S_C(\cdot, \cdot)\) between adjacent frame pairs using the [CLS] token from ViT, resulting in a sequence of similarity scores \(\{c_1, c_2, \ldots, c_{n-1}\}\), where \(c_i = S_C ({\rm ViT}(v_i), {\rm ViT}(v_{i+1}))\).
- Calculate the depth score for each point as \(d_i = \left(cl_i+cr_i-2c_i\right)/{2}\), where \(cl_i\) and \(cr_i\) are the highest score to the left and right of \(c_i\), respectively. A higher depth score indicates that the surrounding similarity is greater than at the point itself.
- Calculate the expectation \(\mu\) and variance \(\sigma\) of the depth scores \(\{d_1, d_2, \ldots, d_{n-1}\}\). Set the segmentation threshold as \(\mu + \alpha \cdot \sigma\), where \(\alpha\) is a hyperparameter controlling the likelihood of segmenting the video.
- Select the \(K-1\) depth scores that exceed the threshold to divide the video into \(K\) semantic segments \(\{s_1, s_2, \ldots, s_K\}\). Each segment represents a relatively independent semantic unit consisting of a sequence of frames.
Recurrent Memory Bridge Layers
We devised a novel Recurrent Memory Bridge Layer, implemented as a multi-layer Transformer block, that integrates recurrent memory tokens within bridge layers to enhance the linear layer’s memorization ability.
For each video segment \(s_i\), we prepend a fixed number of memory tokens, denoted as \([m_i; s_i]\), where \(m_i\) represents the memory tokens. Subsequently, we apply standard self-attention to this sequence, yielding \([m_{i+1}; o_{i}] = {\rm BridgeLayer}([m_i; s_i])\). Here, \(m_{i+1}\) is the updated memory token, and \(o_{i}\) is the visual representation from the bridge layers.
As such, the Memory Bridge can compress past video into memory tokens while preserving current video scenes through projection without losing detailed information by compressing.
Memory Cache with Retrieval
One of the primary challenges associated with recurrent memory bridge layers is the potential for gradient vanishing, which can impede the model’s ability to learn long-range dependencies. To mitigate this issue, we propose the incorporation of a memory cache with a retrieval strategy designed to preserve previous states of memory.
Memory Attention At each timestep \(i\), the system stores all previous memory tokens in a memory cache, denoted as \(M_i = [m_1, \ldots, m_i]\). We employ a self-retrieval mechanism to update the current memory token \(m_i\). Specifically, we treat \(m_i\) as a query and the concatenated memory cache \(M_i\) as key and value. The model performs a standard multi-head cross-attention operation to integrate information from previous timesteps into the current memory state, yielding the updated memory token
\[m_{i+1} = \text{Softmax}\left(\frac{W_i^Q m_i (W_i^K M_i)^\top}{\sqrt{d_k}}\right) W_i^V M_i,\]where \(W_i^Q, W_i^K, W_i^V\) are weight martices for query, key and value, respectively.
Citation
@article{wang2024videollamb,
title={VideoLLaMB: Long-context Video Understanding with Recurrent Memory Bridges},
author={Wang, Yuxuan and Xie, Cihang and Liu, Yang and Zheng, Zilong},
journal={arXiv preprint arXiv:2409.01071},
year={2024}
}